Nodes summary en
The Aristotle University of Thessaloniki's computing cluster "Aristotle" consists of heterogeneous compute nodes grouped by partition. In each queue the nodes are homogeneous (of the same type) and are interconnected either via InfiniBand (14G or 200G) or Ethernet (1G or 10G) networks.
Aristotle Cluster architecture
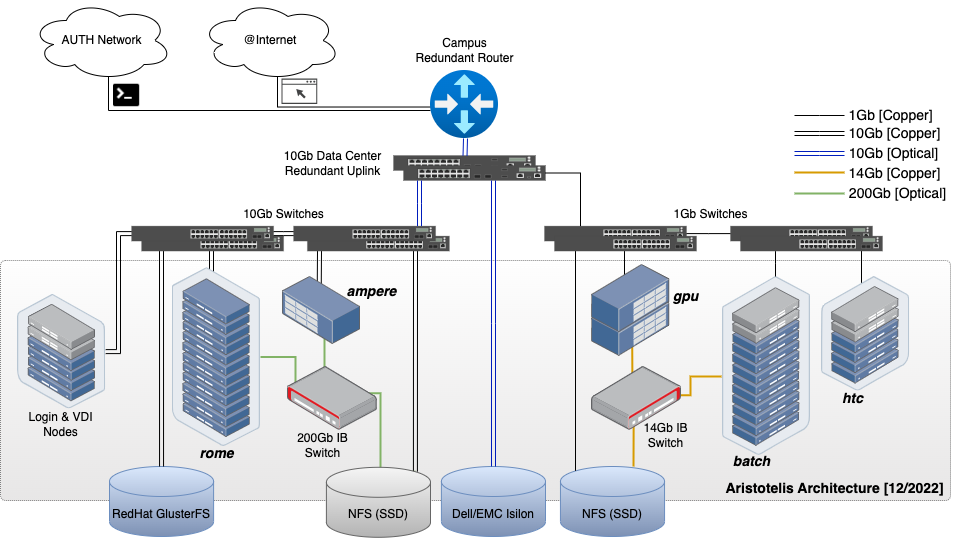
The partitions' characteristics are as shown in the following table.
| Ουρά εργασιών | batch | ampere | gpu | rome | a4000 | ondemand | testing |
|---|---|---|---|---|---|---|---|
| Πλήθος κόμβων (nodes) | 17 | 1 | 2 | 16 | 1 | 12 | 2 |
| Πλήθος CPU Cores ανά κόμβο | 20 | 128 | 20 | 128 | 10 | 12 | 8 |
| Πλήθος Job slots (CPU only jobs) | 340 | 128 | 40 | 2048 | 10 | 144 | 16 |
| Μνήμη ανά κόμβο[GB] | 128 | 1024 | 128 | 256 or 1024 | 128 | 47 | 16 |
| Μοντέλο CPU | Intel Xeon E5-2630 v4 | AMD EPYC 7742 | Intel Xeon E5-2640 v4 | AMD EPYC 7662 | [Intel Xeon Silver 4210R CPU] | Intel Xeon Gold 6230 (vCPU) | Intel Xeon E5405 |
| Interconnect | 14Gb InfiniBand FDR (οδηγίες) | 200Gb InfiniBand HDR (οδηγίες) | 14Gb InfiniBand FDR (οδηγίες) | 200Gb InfiniBand HDR (οδηγίες) | 1Gb Ethernet | 1Gb Ethernet | 1Gb Ethernet |
| Σχόλιο | Η "default" ουρά | Οχτώ κάρτες NVIDIA A100 (40GB DDR6 RAM/κάρτα) σε έναν κόμβο | Μία κάρτα NVIDIA Tesla P100 ανά κόμβο | Ουρά που διατίθεται αποκλειστικά για παράλληλα (mpi ή openmp) jobs. Περισσότερες πληροφορίες ακολουθούν στο infobox παρακάτω. | Μία GPU κάρτα αρχιτεκτονικής [Nvidia RTX A4000] με 16GB GDDR6. Ουρά κατάλληλη για απομακρυσμένη επιφάνεια εργασίας, interactive εφαρμογές με γραφικό περιβάλλον και deep learning αλγορίθμους (οδηγίες) | Μία virtual GPU κάρτα αρχιτεκτονικής Nvidia Quadro RTX 6000 με 6GB GDDR6. Ουρά κατάλληλη για απομακρυσμένη επιφάνεια εργασίας, interactive εφαρμογές με γραφικό περιβάλλον και deep learning αλγορίθμους (οδηγίες) | Ουρά για δοκιμαστικά μικρά (σύντομα) jobs |
The operating system used is Rocky 9 and the Batch system is Slurm.
Using rome partition
The rome partition is reserved exclusively for submiting parallel jobs.
Therefore, before submiting jobs in the rome partition make sure that your application is parallel and
utilizes the following resources (CPU, Memory, Interconnect) to a satisfactory (or optimal) degree.
To check whether a (completed) project has made satisfactory use of the
underlying resources you can use the seff command, e.g:
# seff jobid
seff example and explanation
In the following example we see the seff output for a job that was executed in the batch partition
in 6 CPU Cores (one node):
# seff 1584940
Job ID: 1584940
Cluster: aristotle
User/Group: pkoro/pkoro
State: COMPLETED (exit code 0)
Nodes: 1
Cores per node: 6
CPU Utilized: 00:35:42
CPU Efficiency: 97.01% of 00:36:48 core-walltime
Job Wall-clock time: 00:06:08
Memory Utilized: 2.12 GB (estimated maximum)
Memory Efficiency: 5.63% of 37.69 GB (6.28 GB/core)
We note that a very good CPU efficiency has been measured (97.01%) so the job is suitable for
submission to the rome partition. This evaluation should be repeated as we increase the number of
of CPU Cores.
Administrator actions
If it is found that there are jobs being executed that are underutilizing (e.g. at 60% or higher) the underlying resources, the user will be immediately informed with an automated message of the problem and the jobs will be cancelled.
!!!! question "Questions regarding job efficiency" For any questions or help you would like to ask regarding parallelism and job efficiency please contact us athpc-support@auth.gr.
Partition Limits¶
The following limits are defined for the partitions of the cluster via the Slurm batch system.
| Ουρά εργασιών | batch | ampere | gpu | rome | htc | ondemand | testing |
|---|---|---|---|---|---|---|---|
| Max CPUs per user | 140 | no limit | no limit | 1024 | 200 | 12 | no limit |
| Max Running jobs per user | 20 | 6 | no limit | 50 | 200 | 4 | no limit |
| Max Submitted jobs per user | 500 | 20 | no limit | 60 | 2000 | 8 | no limit |
| Max Nodes per job | 5 | no limit | no limit | no limit | 3 | 1 | no limit |
| Max Runtime per job | 7 days | 6 hours | 1 day | 2 days | 9 days | 2 days | 1 day |
| Min CPUs per job | 1 | 1 | 1 | 8 | 1 | 1 | 1 |
| Min GPUs per job | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| Max GPUs per job | 0 | 8 | 2 | 0 | 0 | 0 | 0 |
Possibility of extending time limits
In batch, rome and ampere partitions there is the possibility of extending the maximum time limit by using one of the following QoSs (Quality of Service):
| Partition | QoS | Additional imposed limitations | Max walltime |
|---|---|---|---|
batch |
batch-extd |
max running CPUs = 40 |
12 days |
rome |
rome-extd |
max running CPUs = 384 |
12 days |
ampere |
ampere-extd |
max running GPUs = 4 |
6 days |
In order to be able to use one of the above QoSs, the user must contact hpc-support@auth.gr.
When access to an extended QoS has been granted, one must specify within each
submission script which QoS is to be used, by setting the qos parameter. For example:
$ #SBATCH --qos=batch-extd