CUDA
Εισαγωγή στη CUDA¶
Η CUDA είναι μια πλατφόρμα παράλληλου προγραμματισμού που αναπτύχθηκε από την Nvidia το 2007. Έκτοτε έχει εξελιχθεί και απλοποιηθεί σε μεγάλο βαθμό. Ο κύριος στόχος της CUDA είναι να δώσει στον προγραμματιστή τη δυνατότητα να χρησιμοποιήσει την τεράστια υπολογιστική ισχύ μιας κάρτας γραφικών (της Nvidia συγκεκριμένα) για να κάνει γενικού σκοπού υπολογισμούς χωρίς να γράψει Assembly ή να χρησιμοποιήσει δύσκολα APIs όπως το DirectX και το OpenGL.
Για να καταλάβουμε λίγο τι τάξης μεγέθους βελτίωση της ταχύτητας μπορούμε να έχουμε, μπορούμε να συγκρίνουμε τον αριθμό των πυρήνων σε μια CPU και μια GPU. Ενας συνηθισμένος επεξεργαστής οικιακής χρήσης έχει συνήθως 2-8 πυρήνες. Μια κάρτα γραφικών οικιακής χρήσης με το ίδιο κόστος περίπου μπορεί να έχει και 1000. Η CUDA μας δίνει τη δυνατότητα να προγραμματίσουμε αυτούς τους πυρήνες πρός όφελος μας.
Το μοντέλο της CUDA¶
Αν και η CUDA υποστηρίζεται πλέον από πληθώρα γλωσσών προγραμματισμού, εμείς θα επικεντρωθούμε στη C++. Θα πρέπει να ξεκαθαρίσουμε ότι η χρησιμότητα της έχει κάποια όρια. Γενικότερα, όσο πιο σειριακό είναι ενα πρόγραμμα, τόσο πιο αχρείαστη είναι.
Όπως αναφέραμε ήδη, η CUDA είναι ενα μια πλατφόρμα παράλληλου προγραμματισμού και όχι απλά κάποιες επιπλεόν εντολές που προστίθενται με μια βιβλιοθήκη. Για να γράψουμε σωστό και αποτελεσματικό κώδικα θα πρέπει να έχουμε κατανοήσει τον τρόπο που δουλεύει αυτό το μοντέλο.
Μοντέλο εκτέλεσης¶
Όπως είπαμε η διαφορά μιας κάρτας γραφικών από έναν επεξεργαστή έγκειται στον αριθμό των πυρήνων του επεξεργαστή ή για την ακρίβεια στα threads. Τα threads μπορούν να χαρακτηριστούν ως λογικοί πυρήνες και η υλοποίηση τους βασίζεται σε μια μίξη hardware και software. Δεν θα αναφερθούμε περισσότερο όμως γιατί θα ξεφύγουμε από το σκοπό αυτού του οδηγού. Στην CUDA υπάρχουν τρία "στοιχεία εκτέλεσης":
-
Το thread το οποίο είναι και το μικρότερο δυνατό. Μπορούμε να το φανταστούμε σαν εναν πυρήνα επεξεργαστή.
-
Τα thread blocks τα οποία είναι ενα σύνολο απο threads όπως υποδηλώνει και το όνομα τους.
-
Το grid το οποίο είναι το σύνολο των thread blocks.
Θα δούμε στη συνέχεια πώς μέσα από τον κώδικα μας μπορούμε να ελέγξουμε τα παραπάνω στοιχεία.
Μοντέλο αποθήκευσης¶
Στην CUDA υπάρχουν διάφορα είδη μνήμης, το κάθε ενα για διαφορετική χρήση και με διαφορετικά πλεονεκτήματα/μειονεκτήματα. Ο κύριος τρόπος με τον οποίο γίνεται ο διαχωρισμός είναι το scope. Έτσι έχουμε:
-
Local memory στην οποία έχει αποκλειστική πρόσβαση το κάθε thread.
-
Shared memory στην οποία έχουν πρόσβαση τα thread ενος block.
-
Global, constant, texture memory στις οποίες έχουν πρόσβαση όλα τα threads καθώς και η CPU. Οι δύο τελευταίες έχουν τη διαφορά πως είναι cached και read-only.
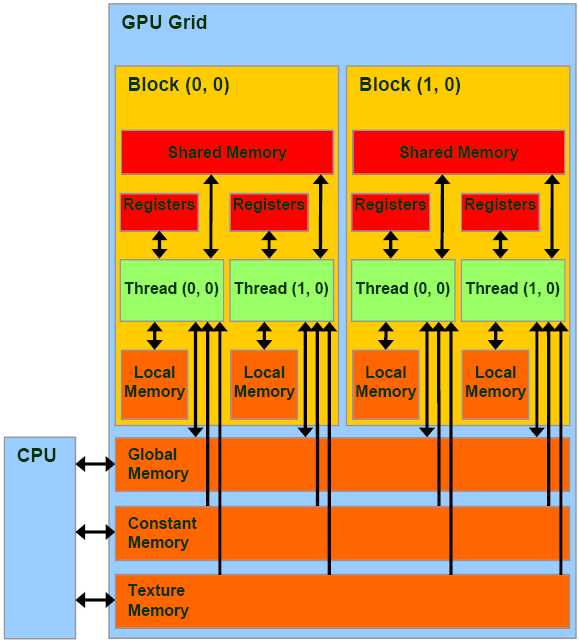
Η χρήση του κάθε τύπου μνήμης μπορεί να αποφέρει σημαντικές βελτιώσεις στην απόδοση του κώδικα μας αλλα είναι προχωρημένο θέμα και δεν θα μας απασχολήσει στη συνέχεια.
Unified Memory¶
Το σημαντικότερο ίσως χαρακτηριστικό που βοήθησε στη διευκόλυνση του προγραμματισμού με την CUDA είναι το λεγόμενο Unified Memory. Αυτό ουσιαστικά είναι ένα μοντέλο διαχείρισης της μνήμης από την ίδια την CUDA και παρέχει στον προγραμματιστή μια κοινή μνήμη. Πιο συγκεκριμένα σε αυτήν τη μνήμη έχει πρόσβαση κάθε κάρτα γραφικών του συστήματος και ο επεξεργαστής. Δηλαδή, μπορούμε να προσπελάσουμε με εναν απλό C/C++ pointer την ίδια μνήμη είτε γράφουμε κώδικα για CPU είτε για GPU, καλώντας απλά ενα έτοιμο API!
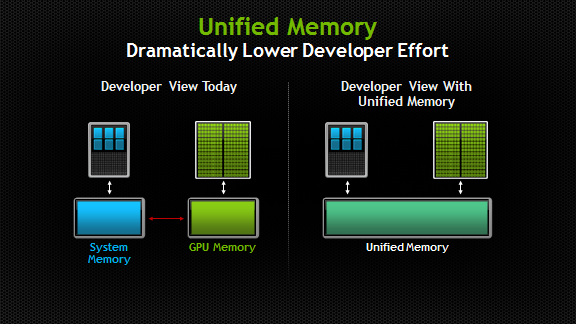
Unified (Virtual) Memory
Όπως μπορεί να καταλάβατε ήδη, η Unified Memory είναι μια εικονική μνήμη και οχι κάποια νέα επαναστατική αρχιτεκτονική μνήμης. Η Nvidia όμως επέλεξε αρχικά το συγκεκριμένο όνομα μάλλον για λόγους Marketing. Από την έλευση των Pascal GPU όμως και μετά, υπάρχει και hardware το οποίο βοηθάει στο virtualization.
Μετά από αυτή την συνοπτική περιγραφή του μοντέλου της CUDA είμαστε έτοιμοι να προχωρήσουμε στη χρήση της.
Χρήση της CUDA¶
Απαιτήσεις¶
Για να γράψουμε ενα πρόγραμμα με CUDA χρειαζόμαστε 2 πράγματα:
-
Μια Nvidia κάρτα γραφικών που να υποστηρίζει CUDA (όλες απο το 2010 και μετα).
-
To CUDA Toolkit το οποίο είναι ένα περιβάλλον προγραμματισμού που περιέχει compilers, debuggers και διάφορα αλλα εργαλεία.
Function execution specifiers¶
Η "καρδιά" της CUDA είναι τα λεγόμενα kernels. Αυτά είναι κανονικές C++ συναρτήσεις τις οποίες μπορούμε να καλέσουμε από οποιαδήποτε συσκευή και να τρέξουν στη GPU με τις ρυθμίσεις που δίνουμε. Για να ορίσουμε ενα kernel γράφουμε μπροστά από το όνομα και τον τύπο της συνάρτησης (void υποχρεωτικά) το keyword __global__. Για να το καλέσουμε χρησιμοποιούμε τη σύνταξη
kernel_name<<<x,y>>>(parameters)
όπου:
-
x είναι ο αριθμός των thread blocks.
-
y είναι ο αριθμός των threads ανα block και είναι πολλαπλάσιο του 32. Ο μέγιστος αριθμός εξαρτάται από την κάρτα γραφικών. Στην Tesla P100 για παράδειγμα είναι 2048.
-
parameters είναι οι παράμετροι που θέλουμε να δώσουμε στη συνάρτηση.
Εκτός απο το __global__ υπάρχουν και αλλοι execution specifiers οι οποίοι όμως δεν ονομάζονται kernels. Για παράδειγμα:
-
Το keyword
__device__ορίζει μια συνάρτηση η οποία εκτελείται στη GPU και μπορεί να καλεστεί μόνο από αυτή. Δεν μπορεί να συνυπάρξει στον ίδιο κώδικα μια τέτοια συνάρτηση και ενα kernel. -
Το keyword
__host__ορίζει μια συνάρτηση η οποία εκτελείται στον επεξεργαστή και μπορεί να καλεστεί μόνο απο αυτόν. Αν δεν ορίσουμε στον κώδικα κάποιον τύπο, αυτομάτως η συνάρτηση είναι τύπου host.
Unified Memory Allocation¶
Για να κάνουμε υπολογισμούς στη GPU πρέπει να δεσμεύσουμε μέρος σε μνήμη στην οποία έχει πρόσβαση και η ίδια. Εδώ έρχεται η unified memory την οποία είχαμε περιγράψει παραπάνω. Η CUDA παρέχει δύο έτοιμες συναρτήσεις που μας διευκολύνουν:
-
Η
cudaMallocManaged(&x, size)δεσμεύει χώρο στη unified memory ίσο με size bytes τον οποίο μπορούμε να τον προσπελάσουμε μέσω του pointer x, είτε απο device code(gpu) είτε από host code(cpu). Για παράδειγμα:cudaMallocManaged(&x, 10*sizeof(int)); -
Η
cudaFree(x)δέχεται τον pointer που έχει δωθεί σε κάποιαcudaMallocManaged()και απελευθερώνει τον αντίστοιχο χώρο. Για παράδειγμα:cudaMallocManaged(&x, 10*sizeof(int)); cudaMallocManaged(&y, 10*sizeof(float)); ... cudaFree(x);
Not Unified Memory Allocation¶
Σε περίπτωση που η κάρτα που διαθέτουμε δεν υποστηρίζει τη unified memory, είμαστε αναγκασμένοι να χρησιμοποιήσουμε αλλη τακτική. Από τη στιγμή που δεν μπορούμε να αποθηκεύσουμε τα δεδομένα μας σε μια "κοινή" μνήμη, θα τα αποθηκεύσουμε σε δύο διαφορετικές. Στη μία θα μπορεί να έχει πρόσβαση ο επεξεργαστής και στην αλλη η κάρτα γραφικών. Οι συναρτήσεις που μας βοηθούν είναι οι ακόλουθες:
-
Η
cudaMalloc((void **) &d_a, size)δεσμεύει χώρο στην κάρτα γραφικών. Μέσα από το device code μπορούμε να τον προσπελάσουμε μέσω του pointer d_a, τον οποίο στέλνουμε κατά την κλήση του kernel. -
Η
(type *) malloc(size)είναι η γνωστή C συνάρτηση για δυναμική δέσμευση χώρου. Στη C++ μπορεί να χρησιμοποιηθεί ηnew type[size]int *a = (int *) malloc(size*sizeof(int)); int *b = new int[size]; -
Η
cudaMemcpy(dest, src, size, direction)χρησιμοποιείται για την αντιγραφή δεδομένων από και πρός τη μνήμη της GPU.-
dest: Pointer που δείχνει στην αρχή της μνήμης όπου θέλουμε να μεταφερθούν τα δεδομένα.
-
src: Pointer που δείχνει στην αρχή της μνήμης από όπου θέλουμε να μεταφερθούν τα δεδομένα.
-
size: Είναι το συνολικό μέγεθος των δεδομένων.
-
direction: Ορίζει την κατεύθυνση και μπορεί να πάρει κάποιες συγκεκριμένες τιμές όπως cudaMemcpyHostToDevice και cudaMemcpyDeviceToHost.
-
-
Η
cudaFree(x)δέχεται τον pointer x που έχει δωθεί σε κάποιαcudaMalloc()και απελευθερώνει τον αντίστοιχο χώρο. -
Η
free(x)είναι η γνωστή C συνάρτηση για απελευθέρωση δυναμικά δεσμευμένου χώρου. Παρόμοια για τη C++ μπορεί να χρησιμοποιηθεί ηdelete [] x.
Compile¶
Για να κάνουμε compile χρειαζόμαστε το αρχείο με τον κώδικα c++/cuda με κατάληξη .cu και το CUDA Toolkit. Η έκδοση του CUDA Toolkit είναι μια πολύ σημαντική παράμετρος που πρέπει να λαμβάνουμε υπόψιν όταν θέλουμε να κάνουμε compile και να τρέξουμε κάποιο CUDA αρχείο. Στην ιδρυματική συστοιχία αυτήν τη στιγμή είναι εγκατεστημένο το CUDA Toolkit 8.0. Με αυτό μπορούν να γίνουν compiled και να τρέξουν οι εργασίες που υποβάλλονται. Στο UI υπάρχει η έκδοση 7.5 και μπορεί να χρησιμοποιηθεί μόνο για compile. Έστω ότι ονομάσαμε το αρχείο cuda_app.cu, τότε θα γράψουμε:
module load cuda
nvcc cuda_app.cu -o cuda_app #compile
./cuda_app #run
Παράδειγμα¶
Έστω ότι έχουμε εναν μονοδιάστατο μεγάλο πίνακα με 2^20 θέσεις και θέλουμε να κάνουμε σειριακή αναζήτηση ενός αριθμού. Προφανώς υπάρχουν και πιο γρήγοροι αλγόριθμοι αλλα εμάς μας ενδιαφέρει η βελτίωση που θα φέρει η CUDA στον συγκεκριμένο.
-
Ενα απλό πρόγραμμα σε C++ είναι αυτό. Αρχικά βάζουμε τιμές σε κάθε θέση του πίνακα και έπειτα ο αλγόριθμος αναζητά μια συγκεκριμένη τιμή επιστρέφοντας τη θέση που βρίσκεται. Από μόνος του δεν είναι κάποιος αργός και απαιτητικός κώδικας αλλα είναι απλός και θα βοηθήσει στην κατανόηση των εννοιών που έχουμε αναφέρει εώς τώρα.
-
Ας ξεκινήσουμε τη μετατροπή σε CUDA. Η συνάρτηση που θέλουμε να παραλληλοποιήσουμε είναι η find οπότε θα προσθέσουμε μπροστά από το όνομα της το keyword
__global__. Στη συνέχεια δεσμεύουμε χώρο στη unified memory με την εντολήcudaMallocManaged(&x, N*sizeof(int));και καλούμε το kernel
find<<<1, 1>>>(N, x, 1000000);με 1 thread και 1 block of threads.
Αυτό είναι ενα πρώτο βήμα αλλα δεν θα εκτελεστεί παράλληλα ο κώδικας μας διότι έχουμε μόνο 1 thread και 1 block. Με τη χρήση της
nvprofμπορούμε να δούμε το χρόνο που χρειάζεται το kernel μας για εκτέλεση. Βλέπουμε πως είναι 289ms περίπου.
-
Συνεχίζοντας αλλάζουμε την κλήση σε
find<<<1,256>>>(N,x,1000000);Τώρα τα threads μας είναι 256 αλλά άμα αφήσουμε έτσι τον κώδικα μας το μόνο που θα γίνει είναι να εκτελεστεί 256 φορές συγχρόνως και να δημιουργηθεί race condition. Οπότε πρέπει να αλλάξουμε και την επανάληψη μας. Εδώ θα χρειαστεί να αναφέρουμε κάποιες πολύ χρήσιμες μεταβλητές της CUDA:
-
Η
threadIdx.xπεριέχει το index του τρέχοντος thread ενός συγκεκριμένου block. -
Η
blockDim.xπεριέχει τον αριθμό των threads σε ενα block. -
Η
blockId.xπεριέχει το index του τρέχοντος block του grid. -
Η
gridDim.xπεριέχει τον αριθμό των blocks του grid.
Χρησιμοποιώντας κάποιες από αυτές τις μεταβλητές θα έχουμε το τελικό kernel
__global__ void find(int n, int *x, int y) { int index = threadIdx.x; int stride = blockDim.x; for (int i = index; i < n; i += stride){ if (*(x+i)==y){ printf("%d",i); } } }Ας αναλύσουμε τη νέα επανάληψη. Αρχικά, ξεκινάμε από το index=0. Το blockDim.x εδώ είναι 256 γιατί τόσο είπαμε εμείς να είναι μέσω της κλήσης. Με μια πρώτη ματιά θα λέγαμε ότι οι τιμές του i θα είναι 0,256,512 κλπ. Και σωστό και λάθος! Το i έχει την τιμή του index το οποίο δεν μένει σταθερό, παίρνει τιμές απο 0-255. Αυτό γίνεται αυτόματα μέσω της CUDA οπότε στην πρώτη επανάληψη θα ελεγχθούν οι πρώτες 256 θέσεις, απο 0-255. Για αυτό στη δεύτερη επανάληψη αυξάνουμε το δείκτη κατά 256 ώστε να ξεκινήσουν να ελέγχονται οι επόμενες θέσεις. Αυτό συνεχίζεται εώς ότου φθάσουμε στο τέλος.
Το νέο αρχείο είναι αυτό και έχει κατάληξη
.cu. Επίσης παρατηρούμε ότι ηcoutαντικαταστάθηκε από τηνprintf. Αυτό γίνεται υποχρεωτικά λόγω του CUDA API. Με τη χρήση τηςnvprofμπορούμε να δούμε και πάλι το χρόνο που χρειάζεται το kernel μας για εκτέλεση. Βλέπουμε πως είναι 1.8ms περίπου άρα έχουμε ήδη πολύ καλή βελτίωση.
-
-
Ωραία όλα αυτά αλλα η κάρτα έχει ακόμη μπόλικη ισχύ την οποία μπορούμε να αξιοποιήσουμε. Αυτό θα το κάνουμε χρησιμοποιώντας και πολλά block of threads. Αρχικά πρέπει να υπολογίσουμε πόσα block χρειαζόμαστε και αν φυσικά η κάρτα μπορεί να τα υποστηρίξει. Στο παράδειγμα μας θέλουμε 2^20/256=4096 blocks of threads το οποίο είναι εφικτό. Άρα, αλλάζουμε τον execution caller
find<<<4096,256>>>(N,x,1000000)και την επανάληψη μας.
int index = blockIdx.x * blockDim.x + threadIdx.x; int stride = blockDim.x * gridDim.x; for (int i = index; i < n; i += stride){ if (*(x+i)==y){ printf("%d",i); } }Κλείνοντας, θα περιγράψουμε αυτές τις τελευταίες αλλαγές. Πλέον έχουμε πολλά blocks τα οποία έχουν 256 thread. Και εδώ ξεκινάει το i=0. Επειδή όμως εξαρτάται από τις "μαγικές μεταβλητές" της CUDA δεν μένει σταθερό αλλα αυτόματα θα πάρει ενα σύνολο τιμών. Απο 0 μέχρι τη μέγιστη τιμή του index που προκύπτει θέτοντας blockIdx.x=4095, threadIdx.x=255 και blockDim.x=256, δηλαδή 2^20-1. Αυτό σημαίνει ότι δεν θα χρειαστεί αλλη επανάληψη! Το βήμα είναι ίσο με τον συνολικό αριθμό των threads που έχουμε "δεσμεύσει" για να καλύψουμε τις περιπτώσεις όπου τα threads της κάρτας γραφικών δεν αρκούν για one-pass calculation. Το τελικό αρχείο είναι αυτό.
Ο χρόνος εκτέλεσης τώρα είναι 180μs περίπου. Δηλαδή έχουμε βελτίωση μιας τάξης μεγέθους σε σχέση με την αρχή!

-
Σε περίπτωση που η κάρτα στην οποία θα τρέξει το πρόγραμμα δεν υποστηρίζει το μοντέλου της Unified Memory, το μόνο που έχουμε να αλλάξουμε είναι ο χειρισμός της μνήμης. Το τελικό αρχείο σε μια τέτοια περίπτωση θα είναι αυτό.
Grid Size¶
Στο προηγούμενο παράδειγμα είδαμε ότι το τελικό μέγεθος του grid μας θα είναι ίσο με το μέγεθος του πίνακα, αρα το kernel θα εκτελεστεί με ενα πέρασμα. Όμως αυτό δεν μπορεί να συμβαίνει πάντα διότι περιοριζόμαστε από το υλικό. Αυτό δεν αποτελεί πρόβλημα, απλά θα εκτελεστεί παραπάνω φορές η επανάληψη. Αυτό που πρέπει να προσέξουμε είναι τα ορίσματα που θα δώσουμε στο kernel function. Το μέγεθος του grid, του block size κλπ εξαρτάται απο την κάθε κάρτα. Για τις κάρτες P100 ισχύουν τα παρακάτω νούμερα:
-
Tesla P100
- Max thread block dim: 1024
- Max grid dim: 2^31-1